The Four AI Guardrails Every Agentic System Needs


In an agentic AI system, access authorization shouldn’t be a single checkpoint, but rather enforced across the entire AI flow:
- Prompt Guardrails (Input Controls):
Block unauthorized or out-of-scope requests before the agent begins execution.
- Data Retrieval Guardrails (Pre-Retrieval Controls):
Ensure only authorized data is retrieved and used by the agent before it ever reaches the model.
- MCP Tool Guardrails ():
Govern which tools, APIs, and services an agent can invoke, and how they are used.
- Output Guardrails (Response Controls):
Inspect and filter generated responses to prevent exposure of sensitive or regulated data.
These guardrails define enforcement. The principles below define how it should be designed.
Across all industries, organizations are deploying agents to automate tasks: resolving customer support tickets, summarizing internal documents, orchestrating workflows across APIs, or retrieving insights from internal data sources. These systems promise dramatic productivity gains, but they also introduce a new security challenge that many organizations are only beginning to understand.
Unlike traditional software applications, agentic AI systems do not operate within rigid, predefined workflows. They reason, plan, and dynamically choose actions to achieve a goal. That means they may access multiple data sources, invoke tools, and generate outputs in ways that were never explicitly scripted by developers.
In other words, you may think AI agents are just following your instructions, but they’re actually capable of making decisions on their own. This shift fundamentally changes how authorization must work, and that’s exactly why organizations should apply these AI guardrails across the entire AI flow.
Why Do AI Agents Require Runtime Guardrails?
Let’s consider a simple example: An enterprise deploys AI agents to help customer support teams resolve billing issues. The agents have access to CRM systems, billing platforms, internal documentation, and analytics dashboards, so they can gather context and respond quickly. Now imagine a support request escalates from a routine question to a billing dispute. The agents retrieve additional data to help resolve the issue. But because they were granted broad permissions to operate efficiently, they may also retrieve sensitive financial records or personal information that the user handling the case was never meant to see. Nothing in the system technically failed. The agents simply used the access they had.
This is the core challenge of agentic AI: if access exists, the agent will eventually use it. That is why authorization must operate continuously across the entire AI interaction flow, not just at login or API access.
Traditional authorization models were designed for deterministic applications with predictable execution paths. Agentic systems, by contrast, operate through probabilistic reasoning and multi-step interactions across systems, tools, and datasets. A single prompt can trigger a chain of actions across APIs, databases, and internal services, dramatically expanding the blast radius of any mistake or overprivileged access. To safely scale AI agents in enterprise environments, organizations must move beyond static access control. Instead, they need runtime guardrails across the entire AI workflow.
In the Authorization for Agentic AI Playbook, we outline four guardrails that define a secure agentic architecture.
The Four Guardrails of Secure Agentic AI
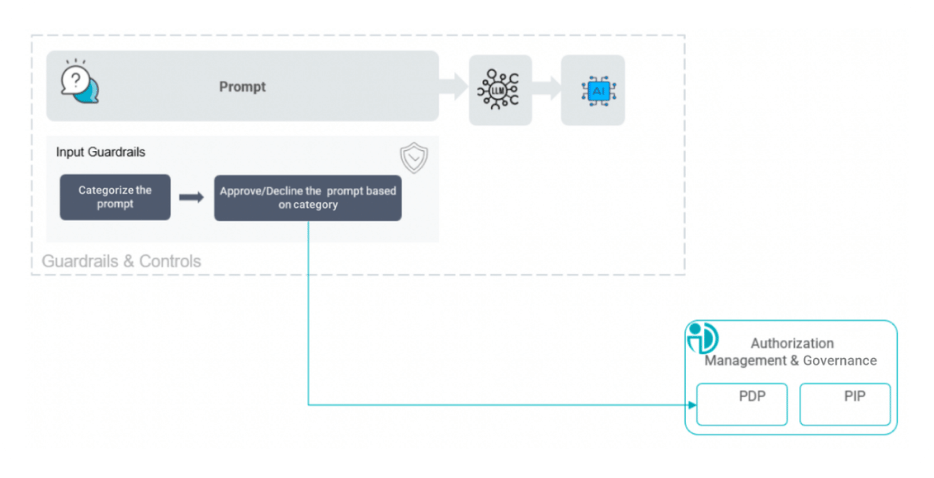
1. Prompt Guardrails to Control the Entry Point
Every AI interaction begins with a prompt. Whether it is a user asking a question or another system triggering an automated workflow, the prompt defines the agent’s initial objective. But what if the person is not even allowed to ask the question? Imagine a Sales Engineer trying to access the organizational Human Resource database. Prompt guardrails evaluate whether the requested task should proceed before the system retrieves data or invokes tools. This includes:
- classifying the prompt by topic,
- identifying the intent of the request,
- and evaluating whether the user and agent are authorized to perform that task.
Unauthorized or high-risk requests can be blocked immediately, preventing the AI pipeline from progressing further. In the above example, with the Input Guardrail, the Sales Engineer would be blocked immediately.
This early control point is critical. If a user is not authorized to access certain information, there is no reason for the agent to retrieve data or generate responses on that topic.
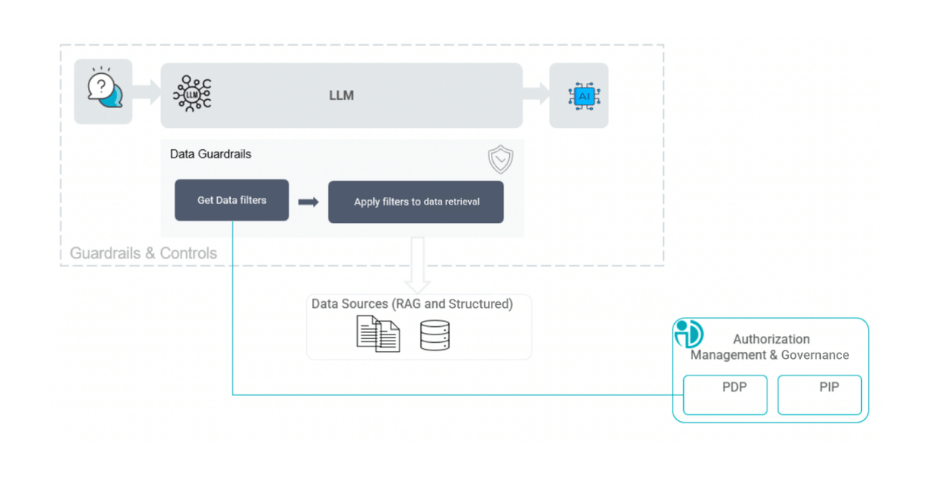
2. Data Retrieval Guardrails to Protect the Largest Risk Surface
Data access represents the most critical authorization surface in agentic AI. Agents rely heavily on structured databases, document repositories, vector stores, and knowledge bases to generate responses. If authorization is not enforced before data retrieval, sensitive information can easily enter the AI pipeline and be incorporated into the model’s reasoning process.
The pre-retrieval guardrail enforces granular filters on RAG workflows before data is retrieved or exposed. Structured data can be filtered at the row or column level, while unstructured content can be restricted based on document classifications or security categories. The key principle is simple: unauthorized data should never enter the AI pipeline at all. If sensitive information is retrieved and embedded into the model’s context, control has already been lost.
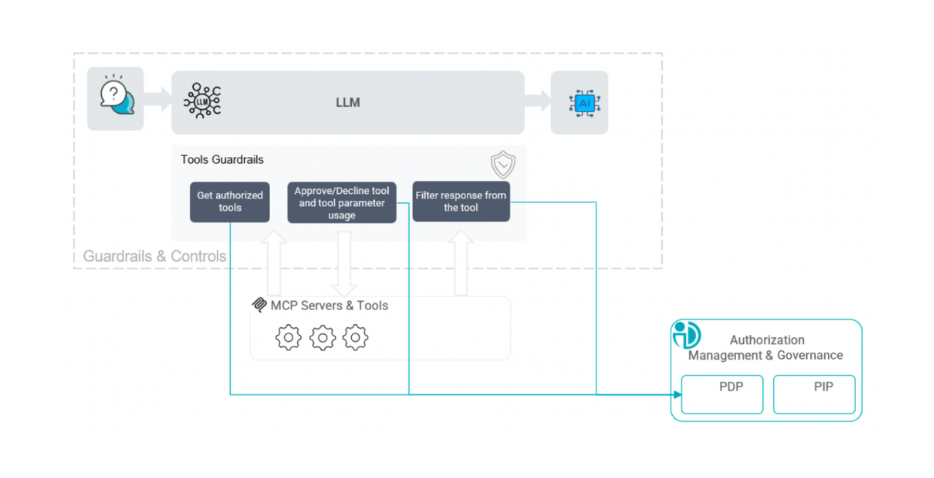
3. MCP Tools Guardrails to Govern the Agent’s Capabilities
Through frameworks and standards such as the Model Context Protocol (MCP), agents can invoke APIs, trigger automation workflows, update databases, or interact with additional agents. This capability dramatically expands the attack surface. Without proper controls, an agent could combine tools in unexpected ways, execute actions beyond its intended scope, or expose sensitive data through external integrations.
MCP tool guardrails govern which services and APIs an agent can access, under what conditions those tools can be invoked, and what parameters are permitted during execution. By dynamically controlling tool usage, organizations ensure that agents operate only within clearly defined boundaries.
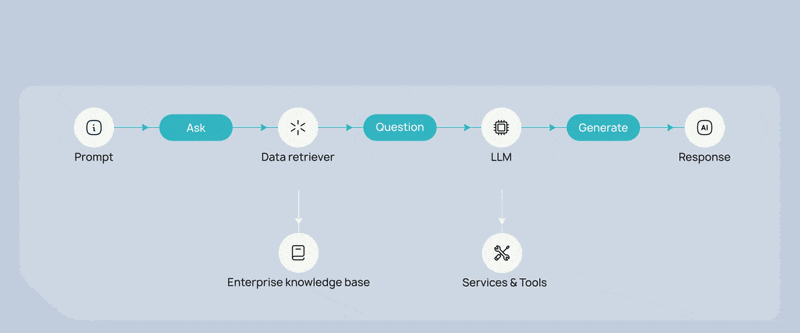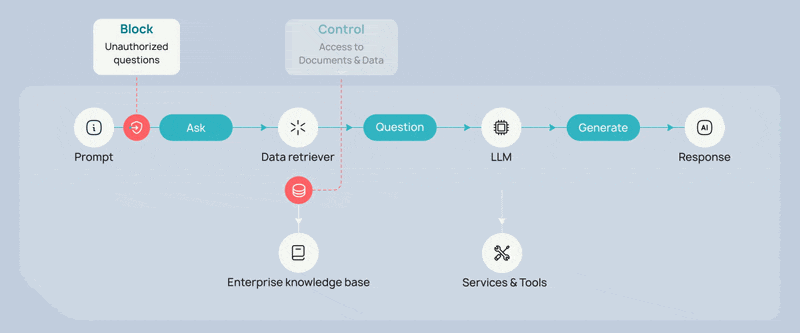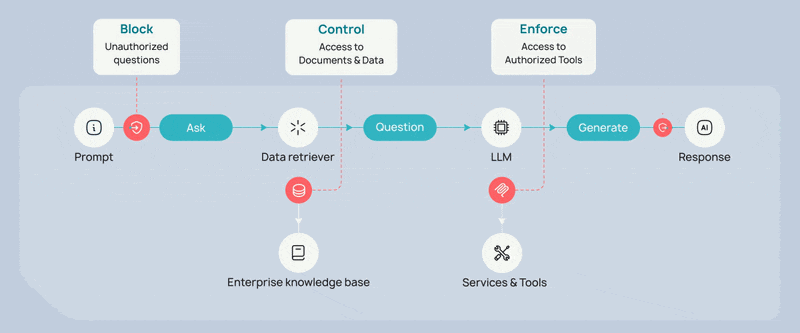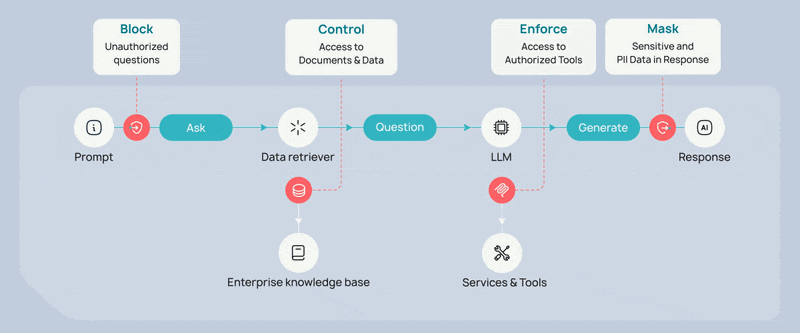
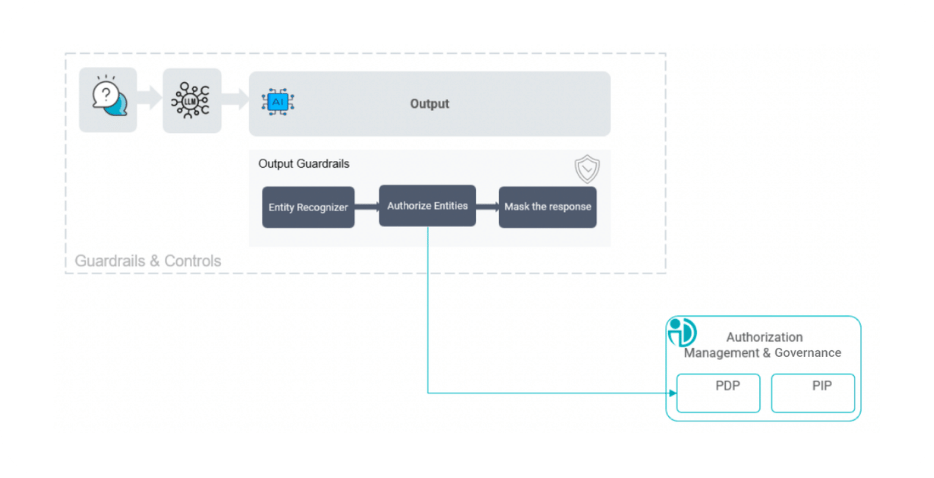
4. Output Guardrails to Control What the Agent Exposes
Even when prompts, data retrieval, and tool usage are properly authorized, sensitive information can still appear in generated responses. Large language models can synthesize insights from multiple sources, and that synthesis may unintentionally expose regulated or confidential information.
Output guardrails inspect generated responses before they are delivered to the user. Sensitive data elements, such as personal identifiers or regulated information, can be dynamically masked, redacted, or filtered based on policy. This final layer ensures that the information leaving the system aligns with organizational policies and regulatory requirements.
From AI Guardrails to AI Governance
These four guardrails represent the core control points of the agentic AI workflow: input, data retrieval, MCP tool invocation, and output generation.
As AI adoption accelerates, security leaders are increasingly recognizing that authorization is no longer just an access control mechanism. It is becoming the control plane that governs what autonomous systems can access, do, and expose.
Organizations that implement these guardrails early will be better positioned to scale AI innovation safely. Those that rely on static permissions… will struggle to keep up.
Download the Authorization for Agentic AI Playbook to learn how to design secure, scalable authorization models for enterprise AI systems.
Related articles

PlainID and Cisco Duo: Real-Time Authorization at SSO Sign-In
PlainID and Cisco Duo are partnering to bring real-time authorization into Duo SSO. When a…

How to Evaluate Enterprise Authorization Management Platforms for Complex Environments
Evaluating an enterprise authorization management platform comes down to six capabilities: centralized policy management, real-time…

PlainID Brings Google BigQuery’s Native Data Controls Into One Control Plane
PlainID’s Data Platform Authorizer Program expands to support Google Big Query in addition to Snowflake,…